Predictive Maintenance Fails in the Last Mile. It’s a Workflow Problem.
Many field service teams today already know when something is going to fail. Your systems are tracking equipment. Your sensors are reporting anomalies. Your dashboards are surfacing alerts before breakdowns actually happen. In theory, this should have changed how your operations run.
But if you look at how work actually gets executed, the pattern has not shifted as much as expected.
- You still receive a complaint.
- You still dispatch after something stops working.
- You still deal with urgency instead of planning.
So the question is not whether you can detect problems early. The question is why early detection is not changing what happens next.
This is where most conversations around predictive maintenance fall short. They focus on visibility, monitoring, and analytics. They rarely focus on what happens after a signal is generated.
The real problem is not detection. It is the last mile between awareness and execution. If your systems cannot translate signals into work automatically, your operations will continue to react, no matter how advanced your monitoring becomes.
The Promise of Predictive Maintenance
For years, predictive maintenance has been positioned as the solution to reactive field operations. The idea is straightforward. If you can detect issues early, you can act before failure. That means less downtime, fewer emergency dispatches, and more predictable service delivery.
With IoT platforms like Cumulocity, this capability is no longer theoretical. Equipment can continuously report its condition. Thresholds can trigger alerts. Systems can identify patterns that indicate potential failure.
On paper, everything needed to move from reactive to proactive service already exists.
- You can monitor assets in real time.
- You can detect anomalies early.
- You can receive alerts before failure occurs.
So it is reasonable to expect that field service operations would now be largely preventative. But that is not what most teams experience.
Even with strong monitoring in place, many operations still rely on reactive workflows. Work orders are created after issues escalate. Dispatch teams respond to urgency instead of planning ahead. Technicians arrive after disruption has already occurred.
This is not because the technology is failing. It is because detection alone does not change execution.
A mobile field service management software platform can surface signals. A mobile field service software setup can show you what is happening across assets. Even a free FSM system with scheduling and mobile capabilities can help you track work more effectively.
But none of these automatically ensure that action follows detection. That is a different problem entirely.
The Reality: Why Teams Still React
To understand why predictive maintenance does not deliver expected outcomes, you need to follow what actually happens after an alert is generated. In most field operations, the workflow looks like this: detect → notify → stall
- A temperature threshold is breached overnight.
- The alert appears in a monitoring dashboard.
- No work order is created.
- No technician is assigned.
- Quickly, the issue has escalated into an outage instead of a scheduled maintenance visit.
The signal exists, but it does not become work. This breakdown is not always obvious at first, because each step appears to function correctly. Monitoring systems detect issues. Notifications are delivered. Data is visible.
But when you look at execution, the gap becomes clear.
- Alerts are generated, but no one owns them
- Notifications are seen, but not prioritized
- Work orders are not created automatically
- Scheduling is not triggered
- Dispatch decisions are delayed
So even though your systems know something is going to fail, your operations are not structured to act on that information in time. As a result, teams continue to operate in a reactive cycle.
- You wait until the issue becomes critical.
- You create a job manually.
- You dispatch based on urgency.
- You resolve after impact.
This is why many teams feel like they have invested in predictive capabilities but are still running break-fix operations. The issue is not that the signals are wrong. It is that the signals are not connected to execution.
And this is where most mobile FSM systems with scheduling and mobile setups fall short. They help you manage work once it exists, but they do not always define how work should be created from signals. That gap becomes more visible as operations scale.
- More assets generate more alerts.
- More alerts create more noise.
- More noise makes it harder to act.
Eventually, teams begin to ignore anything that is not urgent. Alerts lose meaning, and only failures trigger action. At that point, predictive maintenance becomes a reporting tool, not an operational advantage.
If you want to move beyond this, the focus cannot stay on detection. It has to shift to what happens immediately after detection. Because that is where predictive maintenance either succeeds or fails.
Where Predictive Maintenance Actually Fails
At some point, you start to notice something uncomfortable. The problem is not detection. Your systems are doing exactly what they were designed to do. They monitor assets, identify anomalies, and surface signals early. In many cases, they are accurate.
The failure happens after that.
It happens in the transition between knowing and doing. This is what we refer to as the last mile of execution.
The last mile is not a technical layer. It is not another dashboard or another alerting system. It is the moment where a signal should become structured work inside your operations. And in most environments, that transition never happens cleanly.
Instead, the signal sits outside the workflow.
- It exists in a monitoring system
- It appears in a dashboard
- It triggers a notification
But it does not enter the system where work is planned, assigned, and executed. That gap is where predictive maintenance breaks down. Because unless a signal becomes a job, it has no operational value.
You can detect issues days in advance. You can receive alerts in real time. You can even prioritize them based on severity. But if none of that leads to immediate, structured action, your operations will still behave reactively.
This is why many teams feel like they are close to being proactive, but never quite get there. They are solving for visibility, but not for execution.
The Workflow Problem
Once you identify where the breakdown happens, the next realization is more important.
Most predictive maintenance failures are not caused by poor sensing or missing data. They are caused by workflows that were never designed to respond automatically.
Most field operations are not designed to respond automatically to signals. They are designed to respond to jobs. And jobs are still created manually in many environments.
That creates a dependency.
- Someone has to interpret the alert.
- Someone has to decide whether it matters.
- Someone has to create the job.
- Someone has to assign it.
Every one of these steps introduces delay. And more importantly, inconsistency. Different people interpret signals differently. Some alerts get acted on. Others are ignored. Some jobs are created immediately. Others are delayed until escalation.
Over time, this leads to fragmented execution. To understand this clearly, it helps to look at what predictive maintenance actually requires at an operational level. It is not just about detecting early. It is about having a system that is ready to act without hesitation.
For predictive maintenance to work operationally, four things need to happen consistently:
- Defined workflows that map signals to actions
- Clear ownership so alerts are not left unassigned
- Minimal decision-making at the moment of detection
- Structured job creation that happens automatically
If any of these are missing, the system slows down. And once delay is introduced, prevention becomes a reaction. This is why many teams invest in monitoring but do not see a change in outcomes.
They improve detection, but they do not redesign workflows. Even when using a mobile field service management software platform or a field service app free FSM system with scheduling and mobile capabilities, the core question remains the same.
What happens when a signal is generated?
If the answer still involves manual steps, the system is not truly proactive.
What Actually Needs to Happen
Once you shift your focus from detection to execution, the model becomes much simpler. A signal should not create awareness. It should create work.
The moment a threshold is crossed or an anomaly is detected, the next step should already be defined. Not decided in real time, but built into the system. The ideal flow looks like this:
Signal detected
→ Threshold crossed
→ Work order created automatically
→ Context attached to the job
→ Job enters scheduling
→ Technician is assigned
→ Work is completed before failure
Each step flows into the next without manual intervention. There is no pause between detection and action. There is no dependency on someone noticing the alert. There is no delay caused by interpretation. This is the point where predictive maintenance stops being a monitoring exercise and starts functioning operationally.
To make this practical, think about what changes in your day-to-day operations when this flow is in place.
- Instead of reacting, your team starts seeing work earlier.
- Instead of creating jobs manually, jobs appear as soon as a condition is met.
- Instead of prioritizing under pressure, scheduling becomes more structured.
- Instead of technicians arriving after failure, they arrive before it happens.
This shift does not require more data. It requires a different way of structuring how work is created and managed.
In many cases, teams already have the necessary tools. They may be using a mobile field service software setup or a mobile FSM system with scheduling and mobile capabilities that can support these workflows.
The difference lies in how those systems are configured and connected.
Predictive maintenance becomes real when signals are directly tied to job creation, scheduling, and execution. Until that happens, detection remains separate from operations. And as long as that separation exists, teams will continue to react.
For many teams, the transition begins by introducing more structured scheduling, workflow ownership, and mobile execution into day-to-day operations. As operations grow, that foundation becomes critical in supporting more advanced workflows and higher volumes of work.
The goal is not to reduce the complexity of your business. It is to ensure that your systems are capable of handling it. Because in the end, scaling is not about doing more work. It is about delivering that work consistently, clearly, and with confidence.
Bridging IoT to Execution
Once you understand where predictive maintenance breaks down, the next step becomes clearer. The gap is not in detection. It is in how detection connects to execution. Most IoT platforms, including Cumulocity, are designed to do one thing extremely well. They surface signals. They monitor assets, detect anomalies, and trigger alerts when conditions change.
But monitoring alone does not create operational movement.
Someone still needs to decide what happens next. Someone needs to create the work order, assign the job, schedule the technician, and ensure the right information reaches the field. That dependency is where reactive operations continue.
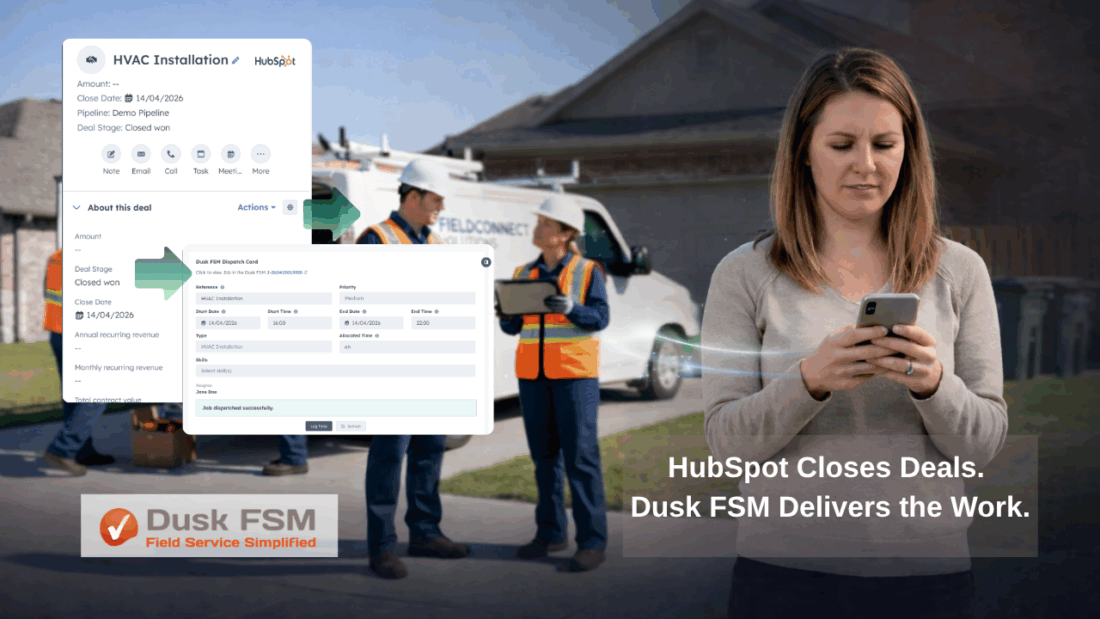
This is where an execution platform like Dusk FSM changes the model.
Not as another tool, but as the layer that translates signals into structured workflows. When connected correctly:
- Alerts do not stay as notifications
- Signals do not require manual interpretation
- Work does not depend on someone creating it
Instead, the system handles the transition.
- A signal becomes a job.
- The job carries context.
- The job enters scheduling.
- The job gets assigned and executed.
Instead of treating alerts as isolated notifications, Dusk FSM allows those signals to move directly into operational workflows. When thresholds are breached or alarms are triggered within Cumulocity IoT, work can be created automatically with the necessary context already attached.
That includes:
- asset information
- location details
- issue type
- job priority
- workflow status
Instead of rebuilding that information manually, the work enters the system ready for scheduling and dispatch. This changes how field operations respond in practice.
Dispatch teams are no longer monitoring dashboards waiting to react. Technicians are no longer sent without context after a failure has already occurred. And operations teams no longer rely on fragmented handoffs between monitoring systems and execution platforms.
The transition from signal to action becomes structured.
- A threshold breach becomes a work order.
- A work order enters scheduling.
- Scheduling drives execution.
That flow matters because predictive maintenance only creates value when execution begins early enough to prevent disruption.
This is also where workflow configuration becomes important. Dusk FSM allows teams to define how different alerts should behave operationally, how work should be categorized, who owns it, and how it moves through scheduling and completion.
That flexibility matters because preventative maintenance workflows are rarely identical across businesses. Different teams operate with different priorities, approval structures, service models, and planning approaches.
The goal is not simply to automate alerts.
It is to ensure that operational response happens consistently, clearly, and without unnecessary manual coordination. When detection systems and execution systems operate together, predictive maintenance stops being a reporting exercise.
It becomes part of how field operations actually run.
What Changes When the Last Mile Is Fixed
When signals are directly connected to execution, the nature of field operations begins to shift. Not dramatically at first, but consistently over time. You start to see changes in how work flows through the system.
- Fewer emergency jobs created at the last minute
- More work planned ahead of time
- Reduced dependency on urgent dispatch decisions
- Better visibility into upcoming workload
The impact is not just operational. It affects how your team experiences the work.
- Dispatchers spend less time reacting and more time planning.
- Technicians arrive with clearer context.
- Supervisors gain a more predictable view of operations.
Most importantly, issues are addressed earlier in the lifecycle. This reduces the compounding effects of failure.
Less downtime. Fewer escalations. More consistent service delivery.
None of this comes from better alerts alone. It comes from ensuring that alerts lead to action without delay.
Why Most Implementations May Still Fall Short
Even with the right tools in place, many teams struggle to fully close the gap between detection and execution. The reason is not lack of capability. It is how systems are set up and used.
A few patterns show up repeatedly.
- Workflows are not clearly defined
- Ownership of alerts is unclear
- Too many manual steps remain in the process
- Systems operate in isolation instead of being connected
In some cases, teams attempt to solve this by adding more configuration or more layers of logic. But complexity often creates new problems. The goal is not to build a complicated system. The goal is to build a system that removes decision-making at the moment of execution. That is what allows signals to move quickly and consistently through the workflow.
If your current setup still requires someone to interpret, decide, and create work manually, the last mile is still dependent on people, not systems. And that is where delays will continue to occur.
From Signals to Action: Making Predictive Maintenance Work
At this point, the pattern becomes difficult to ignore.
Most field operations do not have a detection problem. You already know when something is likely to fail. Your systems surface signals early enough. Platforms like Cumulocity IoT are doing their job.
What is missing is what happens next.
Predictive maintenance does not succeed because you can see the problem earlier. It succeeds when your operations are designed to respond the moment that signal appears.
That requires more than monitoring.
It requires a system where signals automatically become work. Where alerts trigger job creation. Where jobs enter scheduling without delay. Where execution begins without manual intervention.
This is where connecting detection to execution becomes critical.
When platforms like Cumulocity are integrated with an execution layer like Dusk FSM, the last mile disappears. Signals no longer sit in dashboards. They move directly into workflows, into scheduling, and into field execution.
That is what turns predictive maintenance from a concept into a working system. If you are already investing in IoT and monitoring, the next step is not more data. It is ensuring that your systems can act on that data automatically.
👉 Explore how Dusk FSM connects with Cumulocity to turn IoT signals into scheduled field work: https://duskmobile.com/integrations/
Because the real value of predictive maintenance is not in knowing earlier. It is in acting on it in time.
Ready to see the difference?
Get started with the Dusk FSM Platform and see the benefits from streamlining your field operations with a single, comprehensive view of your business in real time. Start collaborating today and excelling in customer service. Read more on our platform capabilities here and a dedicated YouTube video here.
Get Started Today
Not sure where to start? Request a demo from our team via the button below:
Book a Demo
Or you just have some questions: